Este tópico explica como criar uma tarefa de integração para importar ocorrências de vulnerabilidades de um arquivo XML gerado por um scanner que, por padrão, não é suportado pelo sistema.
O sistema já oferece tarefas de integração específicas para os scanners Nexpose e Qualys, mas é através dessa tarefa que é possível importar as ocorrências de vulnerabilidades detectadas por qualquer outro scanner que seja capaz de exportar seus relatórios de coleta para o formato XML. Essas ocorrências são incluídas no catálogo de vulnerabilidades e mapeadas automaticamente para os ativos correspondentes através dos critérios de mapeamento definidos para cada ativo. Para informações sobre o catálogo, veja o Capítulo 8: Conhecimento -> Conhecimento de riscos -> Catálogo de vulnerabilidades.
Os arquivos XML gerados pelos scanners possuem uma determinada estrutura de cabeçalhos, seções e tags de identificação de conteúdo, entre outros elementos. Para que o sistema possa importar as informações acerca dessas vulnerabilidades corretamente, é necessário que o sistema consiga compreender a forma como o relatório XML do scanner está estruturado. Scanners de fornecedores diferentes podem utilizar termos e nomes próprios para identificar as propriedades relevantes das ocorrências de vulnerabilidades. Assim, não há garantia de que os relatórios XML gerados por scanners diferentes usarão um mesmo termo para denotar uma mesma propriedade de uma vulnerabilidade, como, por exemplo, o seu nome, sua categoria ou o seu grau de severidade. Desse modo, para que a importação seja bem-sucedida, é necessário mapear os termos proprietários que aparecem no relatório em XML para designar propriedades das vulnerabilidades para outros termos padronizados que o sistema é capaz de reconhecer.
Por exemplo, um scanner S1 poderá utilizar o termo "Name" em seu relatório XML para identificar os nomes das vulnerabilidades que detectou, ao passo que outro scanner S2 pode utilizar o termo "Vulnerability". Da mesma forma, o scanner S1 pode utilizar o termo "Scoring" para a sua métrica de risco associada à vulnerabilidade, ao passo que o scanner S2 pode utilizar o termo "CVSS", o terceiro scanner S3 pode chamar a sua métrica de "Risk Level", e assim por diante.
Também pode ocorrer que certos scanners incluam certas informações em seus relatórios XML que podem não estar disponíveis nos relatórios gerados por outros scanners. Por exemplo, o scanner S1 pode fornecer informações sobre a categoria das vulnerabilidades que detectou, ao passo que o scanner S2 pode não disponibilizar essa informação. Isso pode ou não ser um problema para a importação desses dados para o sistema. Se o campo deixado em branco é opcional para o sistema, não há nenhum prejuízo na inexistência dos dados no relatório XML gerado pelo scanner. Por outro lado, se um campo esperado como obrigatório pelo sistema (por exemplo, a categoria da vulnerabilidade) não consta no relatório gerado pelo scanner, um erro ocorrerá quando a tarefa de integração for executada. Para evitar este problema, é necessário definir um valor padrão para todos os campos que são obrigatórios e que não são fornecidos no relatório do scanner. Observe que se dois ou mais scanners de vulnerabilidades analisarem o mesmo objeto, a informação não será consolidada e é possível que vulnerabilidades duplicadas dos objetos escaneados sejam reportadas.
Outro recurso que pode ser utilizado nesse mapeamento é a conversão de valores numéricos, dado que diferentes scanners podem utilizar escalas diversas para indicar a severidade ou nível de risco das vulnerabilidades que detectam. Por exemplo, no scanner S1 o nível de severidade da vulnerabilidade pode variar em uma escala que vai de 1 até 10, ao passo que em outro scanner S2 este mesmo parâmetro pode ser medido em uma escala diferente, digamos, de 1 até 5. Desse modo, é possível criar regras para converter os valores de cada scanner para outra faixa de valores que seja adequada para o sistema. No caso do exemplo mencionado, se os valores esperados para a severidade no sistema variassem entre 1 e 5, nenhuma conversão seria necessária para os valores importados do scanner S2, já que o sistema utiliza essa mesma escala. Entretanto, deveriam ser criadas regras para converter os valores do scanner S1 (os valores 1 e 2 poderiam ser convertidos para o valor 1, os valores 3 e 4 seriam convertidos para 2, e assim por diante).
Abaixo, são apresentados todos os campos que devem ser mapeados para registrar cada ocorrência de vulnerabilidade encontrada nos ativos. Para realizar o mapeamento, é necessário informar em qual nó estão localizadas as informações de cada ocorrência em um ativo. Esta configuração é feita pelo basePath através da escrita do XPath absoluto para o respectivo caminho no relatório de vulnerabilidade. A partir deste ponto, os campos devem ser mapeados pelo XPath relativo a este basePath.
|
Campo |
Variável |
Descrição |
Obrigatório? |
Limite/Formato |
|
Endereço IP |
ip |
Deve conter o IP do ativo. |
Sim |
100 caracteres |
|
Nome NetBIOS |
netbios |
Deve conter o nome NetBIOS do ativo. |
Não |
100 caracteres |
|
Nome DNS |
fqdn |
Deve conter o FQDN do ativo. |
Não |
100 caracteres |
|
ID da Vulnerabilidade |
id |
Deve conter o ID da vulnerabilidade. |
Sim |
N caracteres |
|
Vulnerabilidade |
name |
Deve conter o nome da vulnerabilidade. |
Sim |
N caracteres |
|
Categoria |
category |
Deve conter um nome para categorizar um grupo de vulnerabilidades. |
Sim |
100 caracteres |
|
Tipo |
type |
Deve conter o tipo de vulnerabilidade. Deve ser mapeado para os seguintes valores: confirmed, potential ou info. |
Sim |
N/A |
|
Nível |
level |
Deve possuir uma pontuação entre 1 e 5, que será utilizada para cálculo de risco. |
Sim |
1-5 |
|
Descrição |
description |
Deve conter a descrição da vulnerabilidade. |
Não |
N caracteres |
|
Impacto |
impact |
Deve conter a informação do possível impacto que a exploração da vulnerabilidade poderia ter. |
Não |
N caracteres |
|
Solução |
solution |
Deve conter a solução para a vulnerabilidade. |
Não |
N caracteres |
|
Protocolo |
protocol |
Deve conter o protocolo onde a vulnerabilidade ocorre. |
Não |
100 caracteres |
|
Porta |
port |
Deve conter a porta onde a vulnerabilidade ocorre. |
Não |
Int |
|
Evidência |
evidence |
Deve conter as informações que demonstram a ocorrência da vulnerabilidade para o respectivo ativo. |
Não |
N caracteres |
|
CVSS Score |
cvss |
Deve conter o CVSS da vulnerabilidade (valor entre 0 e 10). |
Não |
0-10 |
|
BugTraq ID |
bugtraq |
Deve conter o identificador BugTraq da vulnerabilidade. |
Não |
50 caracteres |
|
CVE-ID |
cve |
Deve conter o identificador CVE da vulnerabilidade. |
Não |
50 caracteres |
|
Outras Referências |
reference |
Deve conter referências para os lugares onde podem ser encontradas informações sobre a vulnerabilidade. |
Não |
1024 caracteres |
|
Última Atualização |
lastUpdated |
Deve conter a data de atualização das informações de uma determinada vulnerabilidade em um formato especificado. |
Não |
datetime |
Nota: Para o campo Última Atualização, a data deve ser informada através de um formato específico. Para configurar o formato, veja http://msdn.microsoft.com/en-us/library/8kb3ddd4.aspx.
<lastUpdated field="../scan_time" format="MMM dd HH:mm:ss yyyy" />
Os seguintes recursos também estão disponíveis:
•Conversão/mapeamento de valores para adequação aos requisitos do sistema. Um exemplo nítido é a necessidade da conversão dos tipos Tipo e Nível:
<mappings> <add from="Critical Problem" to="confirmed" /> </mappings>
ou
<mappings> <add from="10" to="5" /> </mappings>
•Converter conteúdo em um hash md5. No exemplo, este recurso é utilizado para o campo ID da Vulnerabilidade, já que o scanner que provê as informações não fornece um identificador numérico para vulnerabilidade.
<id field="description" hashed="true" />
•Definir um valor padrão para campos inexistentes no relatório.
<category field="category" default="Unknown" />
•Realizar particionamento de um texto para criar uma listagem de elementos. Os campos BugTraq ID, CVE-ID e Outras Referências são representados por uma lista no sistema. Vários scanners tratam essa lista como um texto com todos estes elementos concatenados e separados por ponto-e-vírgula (;).
<cve field="cve" splitChar=";" />
•Limitar o tamanho de cada tipo de texto para respeitar os limites informados na tabela acima. Caso isso não seja definido, ocorrerá um erro de importação sempre que o conteúdo for superior ao limite permitido. O padrão é truncate="false", pois desta forma é mais fácil identificar erros na montagem do arquivo de configuração.
<reference field="reference" truncate="true" />
O exemplo abaixo é a configuração para um relatório baseado em ativos, onde cada ativo possui uma lista com N vulnerabilidades.
<?xml version="1.0" encoding="utf-16"?>
<config version="1" source="MySample">
<baseNode basePath="/report/details/host_info/vulnerability">
<occurrence>
<id field="description" hashed="true" />
<ip field="../ipaddr" />
<netbios field="../netbios" />
<fqdn field="../hostname" />
<name field="description" />
<category field="category" default="Unknown" />
<type field="severity">
<mappings>
<add from="Critical Problem" to="confirmed" />
<add from="Area of Concern" to="confirmed" />
<add from="Potential Problem" to="potential" />
<add from="Service" to="potential" />
<add from="Other Information" to="info" />
</mappings>
</type>
<level field="severity">
<mappings>
<add from="Critical Problem" to="5" />
<add from="Area of Concern" to="5" />
<add from="Potential Problem" to="3" />
<add from="Service" to="2" />
<add from="Other Information" to="1" />
</mappings>
</level>
<description field="description" />
<impact field="impact" />
<solution field="resolution" />
<protocol field="protocol" />
<port field="port" />
<evidence field="vuln_details" />
<cvss field="cvss" />
<bugtraq field="bugtraq" splitChar=" "/>
<cve field="cve" splitChar=" " />
<reference field="reference" truncate="true" />
<lastUpdated field="../scan_time" format="MMM dd HH:mm:ss yyyy" />
</occurrence>
</baseNode>
</config>
Como o baseNode deve conter o caminho do nó do relatório que representa a ocorrência, o caminho foi configurado para "/report/details/host_info/vulnerability". Já as informações do ativo devem ser buscadas no nó acima (por exemplo, …/ipaddr).
Para o campo Categoria, foi necessário especificar um valor padrão "Unknown" para que não ocorram erros ao importar vulnerabilidades sem esta definição.
Neste scanner, para obter as informações do tipo de vulnerabilidade e nível, que são obrigatórias, foi necessário mapear o conteúdo do campo Severidade para que ele pudesse induzir os valores apresentados.
Para os campos CVE-ID e BugTraq ID é necessário utilizar o splitChar para que a importação reconheça que o conteúdo do relatório é um texto que representa uma lista desses itens separados por um único espaço (" ").
Para o campo Outras Referências, foi necessário utilizar o truncate, já que o scanner utilizado apresenta mais caracteres do que o limite permitido.
As seguintes estruturas de relatórios são aceitas:
•Estrutura baseada em ativos que possuem a lista de vulnerabilidades:
<nó do ativo A>
<nó da vulnerabilidade 1/>
<nó da vulnerabilidade 2/>
…
<nó da vulnerabilidade N/>
</nó do ativo A>
<nó do ativo B>…</nó do ativo A>
…
<nó do ativo Z>…</nó do ativo Z>
•Estrutura baseada em vulnerabilidade ou ocorrência, onde cada nó da vulnerabilidade/ocorrência possui informação do ativo.
<ocorrência A>…</ocorrência A>
<ocorrência B>…</ocorrência B>
…
<ocorrência Z>…</ocorrência Z>
Atualmente não é permitido configurar relacionamentos. Caso o nó de um relatório não possua todas as informações necessárias e faça referência a outro caminho do relatório através de um identificador, este não conseguirá ser mapeado. Exemplo de estrutura:
<vulnerabilidade 001/>
<vulnerabilidade 002/>
<vulnerabilidade N/>
<ativo A/>
<ativo B/>
<ativo Z/>
<ocorrência 001 x A/>
<ocorrência 001 x B/>
<ocorrência N x Z/>
Os arquivos XML podem ser importados diretamente da sua máquina local ou de um repositório remoto, como uma pasta no servidor onde o Módulo Risk Manager está instalado. Caso você esteja utilizando um ambiente SaaS (Software como Serviço), os arquivos XML deverão ser importados localmente do seu computador.
Para que a importação dos relatórios XML que estão armazenados em um repositório remoto possa ocorrer, o caminho completo dos relatórios deve ser fornecido. Pode ocorrer que existam vários arquivos XML no mesmo diretório, já que o scanner poderá gerar estes relatórios com grande frequência. Porém, mesmo que um relatório já processado pelo sistema permaneça no diretório sem ser apagado juntamente com outros relatórios novos, ele só será importado uma vez.
Caso existam vários relatórios XML gerados pelo scanner que ainda não foram processados no repositório onde é feita a importação dos dados, todos esses relatórios serão importados. Assim, é importante informar em qual ordem diferentes relatórios ainda não processados deverão ser importados. O ideal é que a importação de relatórios pendentes seja feita sempre do mais antigo para o mais recente, visando respeitar a cronologia da detecção das vulnerabilidades. Ao configurar a tarefa de integração para importar arquivos de um repositório remoto, você pode definir se a ordem de importação dos arquivos seguirá a data quando os arquivos foram criados ou o nome dos arquivos.
Se os arquivos XML estiverem disponíveis localmente no seu computador, você poderá selecioná-los diretamente para importação. Nesse caso, a ordem de importação segue a ordem alfabética dos nomes dos arquivos. Tarefas para importação local de arquivos são executadas imediatamente após serem salvas e, portanto, as configurações de agendamento serão ignoradas.
Cada vulnerabilidade associada a um mesmo ativo que conste em um ou mais relatórios XML gerado pelo scanner será importada apenas uma vez. Embora o scanner Qualys possua identificadores únicos para vulnerabilidades, há outros scanners que não possuem esses identificadores e podem reportar em duplicidade uma mesma vulnerabilidade referente a um mesmo ativo. Porém, o Módulo Risk Manager mantém controle sobre isso e utiliza um identificador único para cada vulnerabilidade que se repita em diferentes relatórios, que seja referente a um mesmo ativo. Quando o scanner fornece o identificador único, ele será utilizado. Nos casos onde este identificador não é fornecido, o usuário poderá informar qual campo do relatório XML gerado pelo scanner deverá ser utilizado para a identificação de cada vulnerabilidade.
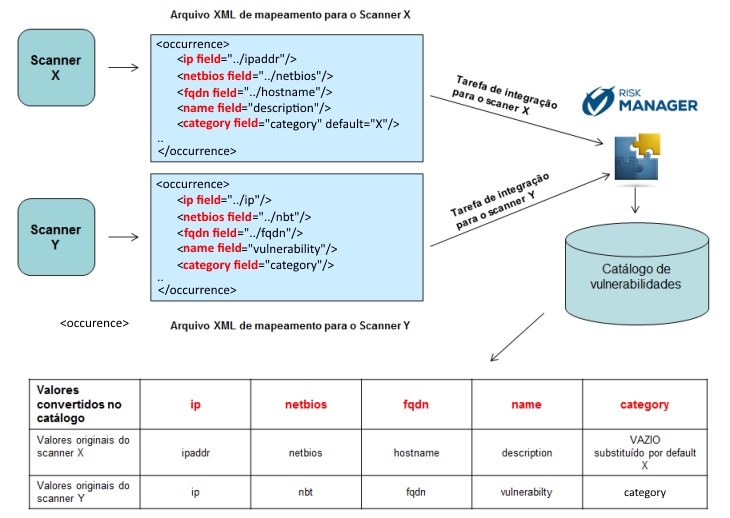
A figura abaixo ilustra os conceitos discutidos até agora. Observe que o dado que o scanner X chama de "ipaddr" e o scanner Y chama de "ip" em seus respectivos relatórios XML serão ambos entendidos como sendo compatíveis com o campo <ip>, que é o nome que o sistema utiliza em seu catálogo para identificar o endereço IP de um ativo analisado. Analogamente, o que o scanner X chama de "description" e o scanner Y chama de "vulnerability" serão entendidos como sendo compatíveis com o campo <name>, que representa o nome de uma vulnerabilidade. Observe também na figura que a categoria da vulnerabilidade que é identificada pelo scanner Y pelo termo "category" não é fornecida pelo scanner X, e então foi fornecido um valor padrão "X" para esse campo para evitar erros durante a importação do relatório gerado por um scanner. Os valores serão armazenados no campo Categoria.
É importante notar que uma tarefa de integração separada terá que ser criada para cada scanner cujas vulnerabilidades se deseja importar. Deste modo, mapeamentos específicos para cada scanner poderão ser configurados.
Ao criar uma tarefa de integração deste tipo, você pode selecionar uma opção que permite que sejam geradas notificações quando ocorrem inconsistências em relação à existência de vulnerabilidades importadas através da tarefa e que mais tarde foram enviadas para tratamento. Por exemplo, se uma vulnerabilidade for identificada através de um scan, depois importada e mapeada para um ativo através dessa tarefa de integração, e então enviada para tratamento através de um projeto de riscos, o sistema irá exibir notificações se a vulnerabilidade não for encontrada em execuções posteriores daquele mesmo scan. Essas notificações irão aparecer no projeto de riscos através do qual a vulnerabilidade foi enviada para tratamento, no módulo Meu Espaço para o usuário que foi alocado como líder do projeto e nas abas Progresso e Associações do evento criado para tratar a vulnerabilidade.
Essas notificações também serão geradas caso um ativo no escopo do projeto de riscos seja removido do arquivo XML que será importado. Isso ocorre porque as vulnerabilidades encontradas para aquele ativo não foram mais encontradas, não necessariamente porque não existem mais, mas porque o ativo já não está mais sendo analisado pelo scanner naquele relatório específico. Se os ativos tiverem sido removidos propositalmente, o arquivo XML deve ser renomeado para evitar que sejam geradas notificações erroneamente. Além disso, o uso de credenciais diferentes ou de uma política diferente para acessar e fazer o scan dos ativos pode evitar que determinadas vulnerabilidades sejam identificadas novamente e gerem notificações erradas.